
ENFJ 비전공자 개발스터디
오라클 데이터베이스 Oracle Database 뷰 인덱스 시노님 시퀀스 파티션 view index synonym sequence partition 본문
오라클 데이터베이스 Oracle Database 뷰 인덱스 시노님 시퀀스 파티션 view index synonym sequence partition
madb 2021. 12. 23. 15:00뷰(view)
뷰는 사용자에게 접근이 허용된 자료만을 제한적으로 보여주기 위해 하나 이상의 기본 테이블로부터 유도된, 이름을 가지는 가상 테이블이다. 뷰는 저장장치 내에 물리적으로 존재하지 않지만 사용자에게 있는 것처럼 간주된다.
즉, 뷰를 생성하면 뷰 정의가 시스템 내에 저장되었다가
SQL 내에서 뷰 이름을 사용하면 실행 시간에 뷰 정의가 대체되어 수행됩니다.
데이터 보정작업, 처리과정 시험 등 임시적인 작업을 위한 용도로 활용된다.
조인문의 사용 최소화로 사용상의 편의성을 최대화 한다.
여러 테이블(기본 관계) 또는 뷰의 데이터를 연결하여 조합할 수 있다.
기본 테이블(table)과 같이 행(column)과 열(row)로 구성되지만, 다른 테이블에 있는 데이터를 보여줄 뿐이며, 실제 테이블과 달리 데이터 자체를 포함하고 있는 것은 아니다. 뷰를 사용하면 여러 테이블이나 뷰를 하나의 테이블인 것처럼 볼 수 있다
하나이상의 테이블로부터 유도되어 만들어진 가상테이블, 실제로 기억공간을 차지하지 않으며 논리적 독립성을 제공하고 데이터 접근 제어로부터 보안성을 향상시킴
정의된 기본 테이블이 삭제되면 뷰도 자동적으로 제거된다.
한번 정의된 뷰는 변경할 수 없으며, 삭제한 후 다시 생성해야 한다.(replace)
검색은 일반 테이블과 동일한 방식으로 한다.
뷰에 대한 삽입, 삭제, 갱신에 대한 제약이 따른다.
컬럼에 기본키가 포함되어 있지 않으면 삽입, 갱신, 삭제가 되지 않는다.
뷰 생성
기존에 있던 테이블에 있는 컬럼에서 원하는 자료만 조회하는 것이기 때문에, 만들 때도 SELECT 문을 통해 생성한다.
CREATE VIEW 뷰이름 AS SELECT 구문;뷰 삭제
DROP SQL 문을 작성한다.
DROP VIEW 뷰이름;인덱스(index)
인덱스란 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다. 만약 우리가 책에서 원하는 내용을 찾는다고 하면, 책의 모든 페이지를 찾아 보는것은 오랜 시간이 걸린다. 그렇기 때문에 책의 저자들은 책의 맨 앞 또는 맨 뒤에 색인을 추가하는데, 데이터베이스의 index는 책의 색인과 같다. 데이터베이스에서도 테이블의 모든 데이터를 검색하면 시간이 오래 걸리기 때문에 데이터와 데이터의 위치를 포함한 자료구조를 생성하여 빠르게 조회할 수 있도록 돕고 있다. 만약, Index를 적용하지 않은 컬럼을 조회한다면, 전체를 탐색하는 full scan이 수행되어 처리속도가 떨어진다.
단일 인덱스 (1개의 컬럼으로 구성)
복합/결합 인덱스 생성 (2개 이상의 컬럼으로 구성)
유니크(UNIQUE) 인덱스
primary_constraint, unique_constraint
id, emp_id 같은 것에 걸면 unique_index
non-unique인덱스
job, dept_no 같은 것에 걸면 non-unique
인덱스 생성시 고려할 사항
테이블의 전체 데이터 중 적은 양을 조회할 때 사용한다.
테이블에 데이터가 적을수록 인덱스의 효율은 떨어진다.
데이터의 유일성이 높을수록, 데이터의 범위가 넓을수록 인덱스의 효율은 올라간다.
NULL이 적은 컬럼이 인덱스 효율이 좋다.
결합 인덱스의 경우 자주 사용되는 컬럼을 앞쪽에 배치한다.
인덱스 삭제
DROP INDEX 테이블이름.인덱스이름
DROP INDEX Table1.IDX_OUTDATE_DESC
시노님 synonym
Alias 같이 이름을 붙여주는 역할과 비슷하다.
다른 유저의 객체를 사용할 때 객체의 이름을 Synonym 으로 이름을 감춤으로 데이터베이스의 보안을 강화하기 위해 사용.
오브젝트명을 짧게하여 SQL문을 단순화 시킬수 있다.
스키마, 오브젝트명(테이블명 등)이 변경 되어도 시노님만 재생성하면 SQL문은 변경하지 않아도 된다.
오브젝트를 외부에 제공할 경우 스키마, 오브젝트명을 숨길 수 있어서 보안에 도움이 된다.
시노님 생성
CREATE [ PUBLIC ] SYNONYM [ 시노님 이름 ] FOR [ 객체 이름 ]
시노님에는 PUBLIC과 PRIVATE타입이 있습니다.
PUBLIC은 모든 사용자가 접근할 수 있고 PRIVATE는 특정사용자에게만 참조가 가능합니다.
PUBLIC을 선언해주지 않으면 기본값으로 PRIVATE가 선언됩니다.
시노님 삭제
DROP SYNONYM 시노님명
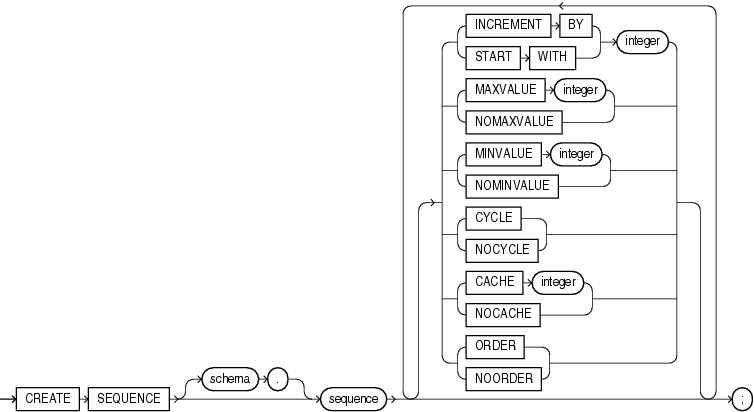
CREATE SEQUENCE [ schema. ]sequence
[ { INCREMENT BY | START WITH } integer
| { MAXVALUE integer | NOMAXVALUE }
| { MINVALUE integer | NOMINVALUE }
| { CYCLE | NOCYCLE }
| { CACHE integer | NOCACHE }
| { ORDER | NOORDER }
]
[ { INCREMENT BY | START WITH } integer
| { MAXVALUE integer | NOMAXVALUE }
| { MINVALUE integer | NOMINVALUE }
| { CYCLE | NOCYCLE }
| { CACHE integer | NOCACHE }
| { ORDER | NOORDER }
]... ;시퀀스 sequence
INCREMENT BY : 시퀀스 실행 시 증가시킬 값
Specify the interval between sequence numbers. This integer value can be any positive or negative integer, but it cannot be 0. This value can have 28 or fewer digits. The absolute of this value must be less than the difference of MAXVALUE and MINVALUE. If this value is negative, then the sequence descends. If the value is positive, then the sequence ascends. If you omit this clause, then the interval defaults to 1.
START WITH : 시퀀스의 시작값이다. (MINVALUE과 같거나 커야 한다)
Specify the first sequence number to be generated. Use this clause to start an ascending sequence at a value greater than its minimum or to start a descending sequence at a value less than its maximum. For ascending sequences, the default value is the minimum value of the sequence. For descending sequences, the default value is the maximum value of the sequence. This integer value can have 28 or fewer digits.
MINVALUE : 시퀀스가 시작되는 최솟값이다.
Specify the minimum value of the sequence. This integer value can have 28 or fewer digits. MINVALUE must be less than or equal to START WITH and must be less than MAXVALUE.
MAXVALUE : 시퀀스가 끝나는 최댓값이다.
Specify the maximum value the sequence can generate. This integer value can have 28 or fewer digits. MAXVALUE must be equal to or greater than START WITH and must be greater than MINVALUE.
NOCYCLE | CYCLE : NOCYCLE (반복안함) Specify NOCYCLE to indicate that the sequence cannot generate more values after reaching its maximum or minimum value. This is the default., CYCLE(시퀀스의 최댓값에 도달 시 최솟값 1부터 다시 시작)
NOCACHE | CACHE : NOCACHE(사용안함), CACHE(캐시를 사용하여 미리 값을 할당해 놓아서 속도가 빠르며, 동시 사용자가 많을 경우 유리)
NOORDER | ORDER : NOORDER(사용안함), ORDER(요청 순서로 값을 생성하여 발생 순서를 보장하지만 조금의 시스템 부하가 있음)
시퀀스 생성 삭제
파티션 테이블 PARTITION BY
파티션이란 테이블에 있는 특정 컬럼값을 기준으로 데이터를 분할해 저장해놓은 테이블.
이때 논리적인 테이블은 1개이지만
물리적으로는 분할한 만큼 파티션이 만들어져 입력되는 컬럼 값에 따라 분할된 파티션별로 데이터가 저장
파티션 테이블을 만드는 목적은 대용량 테이블의 경우 데이터 조회 시 효율성과 성능을 높이기 위한 것
관리적 측면 이점 : 파티션 단위 백업, 추가, 삭제, 변경
성능적 측면 이점 : 파티션 단위 조회 및 DML 수행
PARTITION BY --> GROUP BY와 동일하게 그룹지어 결과를 출력 합니다.
ORDER BY --> PARTITION BY로 정의된 WINDOW 내에서 행들의 정렬순서를 정의해줍니다.
'Database' 카테고리의 다른 글
| 오라클 Oracle SQL 함수 숫자 함수 (0) | 2021.12.28 |
|---|---|
| 오라클 데이터베이스 Oracle Database 표현식 CASE WHEN THEN 조건식 IN, ANY, SOME, ALL, EXISTS, LIKE, BETWEEN (0) | 2021.12.28 |
| 오라클 데이터베이스 Oracle Database SQL Reference (0) | 2021.12.23 |
| 데이터베이스 객체의 종류 (0) | 2021.12.23 |
| 데이터베이스 제약조건 (0) | 2021.12.23 |
